说说360搜索引擎的蜘蛛侠
之前一直有人说,360没有用自己的蜘蛛,而是一个利用其他引擎搜索结果进行整理的元搜索引擎,但是从360搜索出现、发展、到为大家所悉知这一段时间来看,我的一个试验站,捕获了不少360蜘蛛的踪迹。
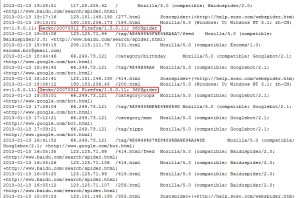
360蜘蛛
事实上说的不少,这个数据在一周的日志统计里面,只出现了74次,有对首页的爬行,有对内页的爬行,而且搜索结果也有相关页面。
依然不排除360蜘蛛再实验性阶段使用的同时,也在使用另一个匿名蜘蛛,当然这只是一种猜测,但是现在的数据已经是能够证实360蜘蛛的存在,虽然爬行量比较小。同时,从爬行记录来看,360蜘蛛是遵循robots.txt规则,nofollow测试也显示360蜘蛛遵循该rel不进行nofollow爬行。
360搜索引擎的出现,虽说现在没有什么太大的关注度,但是从一个长远的角度来看,依然值得去分析研究学习,毕竟360在国内的用户群也算是比较庞大的,虽然没什么正经东西。
- 上一篇:谈谈运营网站应该考虑哪些问题呢?
- 下一篇:互联网做品牌才是王道
相关文章
文章评论
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-
岁月如歌

-
24小时排行
- 最新文章
- 随机文章
